-
WinActorについて
WinActorについて
- 活用シーン
- 導入事例
- イベント・セミナー
- 製品
- WinActorを使う
- トピックス
XPathによりWebページの部品(HTMLの特定箇所) を指定することができます。
画像識別方式とは異なり、画面の表示状態に影響されないことから、安定したブラウザ操作シナリオを作成することが可能です。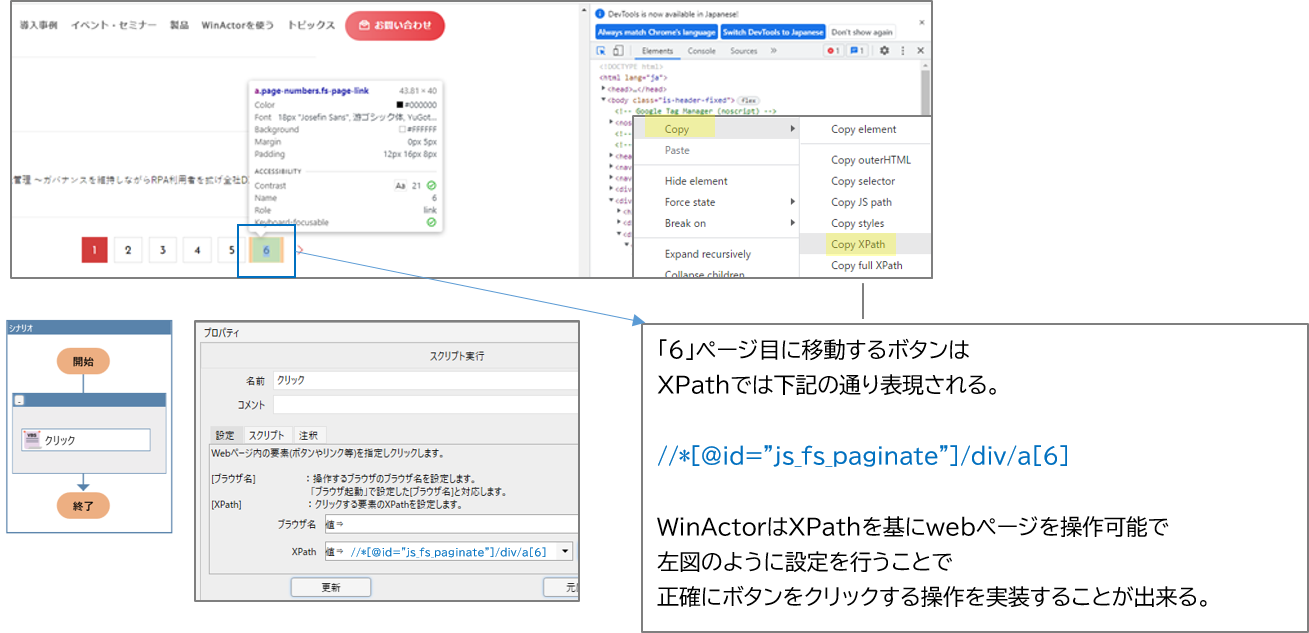
そもそもXPathとは?
XPath(XML Path Language)とは、XML文書の中の特定の要素や属性を指定して、情報を取得するための言語です。
同じタグを使用したツリー構造のマークアップ言語であるHTMLにも適用が可能です。
HTML(Hyper Text Markup Language)との違いは?
HTMLは主にウェブサイトのコンテンツの構造を作るために使用される言語です。XPathはHTMLに記述されている特定の要素を取得するための言語と言えます。
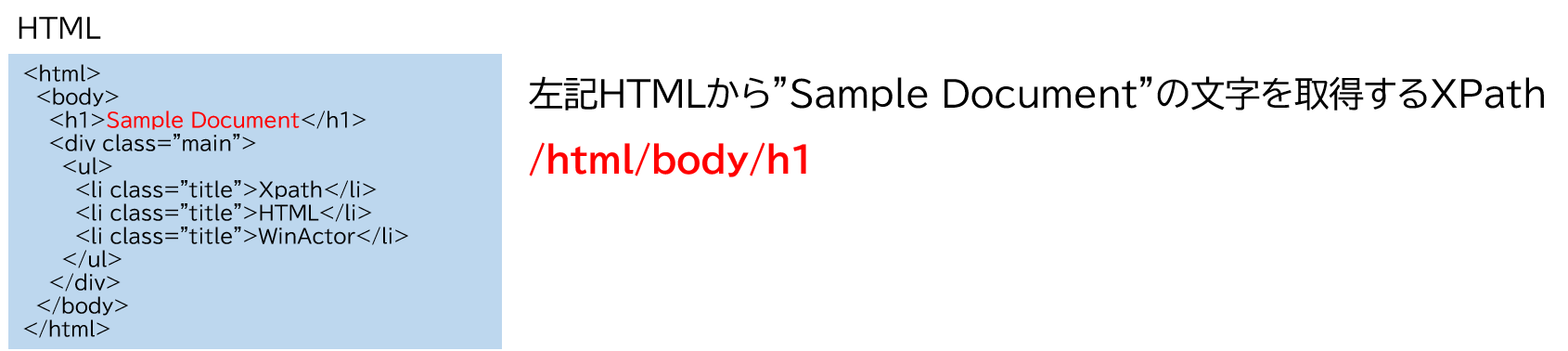
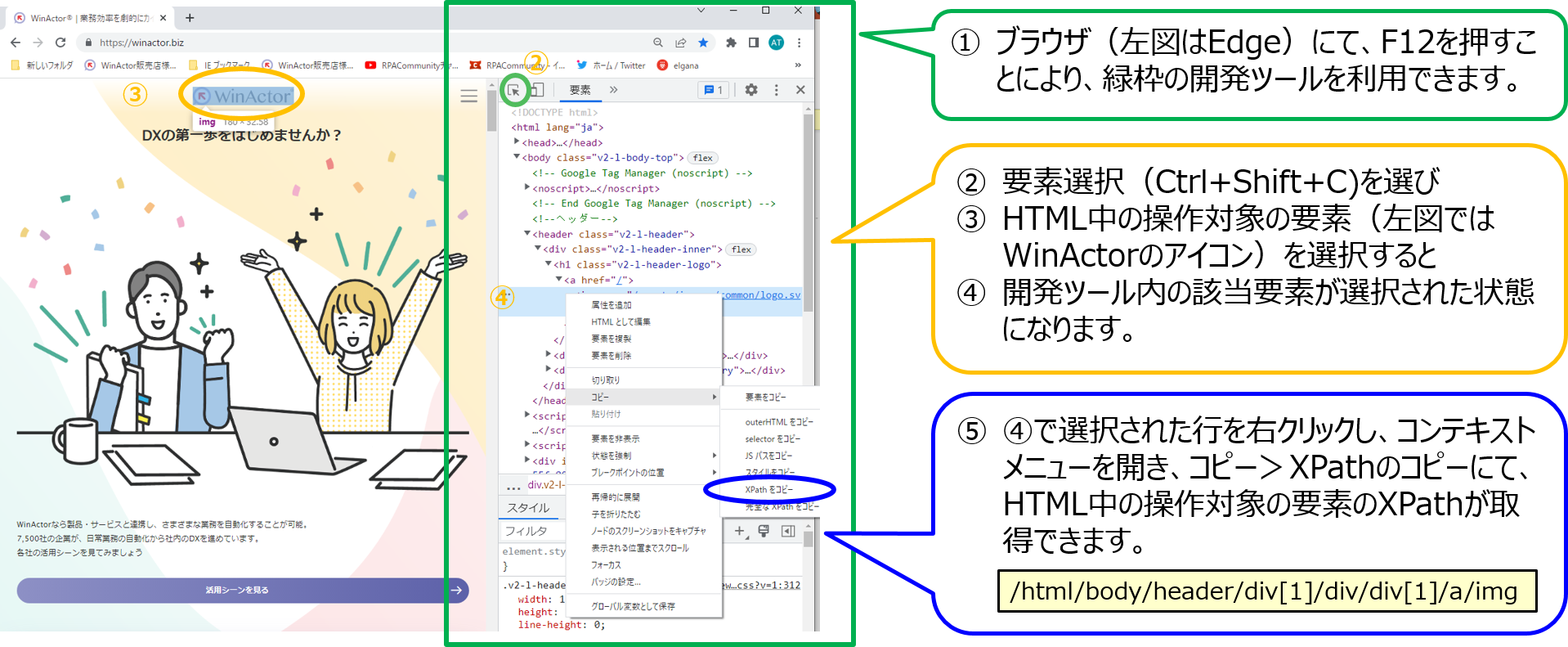
ブラウザ(Edge, Chrome, Firefox)の開発ツール(F12)を利用し、ブラウザに表示しているHTML中の要素のXPathを取得することができます。
WinActorでXPathを活用してもWebページの構造変化には影響を受けてしまいます。
例えば、「 >次のページへ進む 」ボタンをクリックしたいというような以下のケースの場合、
「昨日まで全5ページだったが、 今日は6ページあり、ボタンをクリックできなかった」ということが発生する可能性があります。

![]()
このケースでは、ボタンが6番目の要素であったものが、構造変化により7番目にズレてしまったということになります。
XPathの"関数"を活用することで、このようなケースに対応出来るようになります。
「 >次のページへ進む 」ボタンが要素の最後に設置されるという規則性があることから、要素の最終行をクリックするように設定変更すると
ページ追加によるエラーを回避することが出来ます。
//*[@id="js_fs_paginate"]/div/a[position() = last()]
下記アンケートにお答えいただきますと、アンケート回答終了時の画面にて、XPathについての資料ダウンロードができます。